在随行付的微服务架构演进中,服务间的数据同步与一致性保障一直是系统设计的核心挑战之一。为解决跨服务、跨数据库的数据实时同步与异构数据源整合问题,随行付自主研发了数据同步中间件——Porter。本文将深入探讨Porter的设计理念、核心架构及其在软件开发中的实践应用。
一、Porter的诞生背景与设计目标
随着业务模块的不断拆分与独立部署,各微服务拥有独立的数据库,形成了数据孤岛。传统的数据抽取、转换、加载(ETL)工具在实时性、灵活性和运维复杂度上难以满足高并发、低延迟的金融支付场景。Porter应运而生,其核心设计目标定位于:实现跨数据源的近实时数据同步、保障数据最终一致性、降低业务系统耦合度,并提供高可用、可扩展的运维能力。
二、核心架构与工作原理
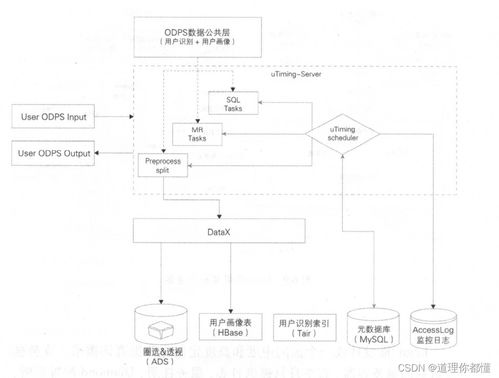
Porter采用基于日志增量捕获(CDC)与消息队列的架构模式,主要由三个核心组件构成:
- 采集器(Collector):以无侵入方式监听源数据库(如MySQL)的二进制日志(Binlog),解析并过滤出变更事件,将其转化为统一格式的消息。
- 消息队列(MQ):作为可靠的中转通道,接收采集器发布的事件消息,起到缓冲、解耦和保证消息有序性的作用。
- 执行器(Executor):订阅消息队列中的事件,根据预定义的规则进行数据转换、映射,并最终写入目标数据存储(可以是另一个数据库、缓存或数据仓库)。
其工作流程可简述为:源库数据变更 → Collector捕获并发布消息至MQ → Executor消费消息并应用至目标库。这种设计确保了数据同步的异步性与松耦合。
三、关键特性与技术创新
- 多模式同步:支持全量同步、增量同步及“全量+增量”混合同步,满足初始化、数据迁移与持续同步等多种场景。
- 灵活的数据过滤与转换:提供基于SQL或配置化的规则,支持按表、按字段、按操作类型(增删改)进行过滤,并能进行简单的数据清洗与格式转换。
- 高可用与容错:采集器与执行器均支持分布式部署与水平扩展,通过 checkpoint 机制记录同步位点,确保故障恢复后数据不丢失、不重复。
- 监控与运维:提供丰富的管理控制台,实时监控同步延迟、数据流量、组件健康状态,并具备告警与可视化链路追踪能力。
四、在软件开发中的实践应用
在随行付的支付、风控、账务等核心系统中,Porter扮演着关键角色:
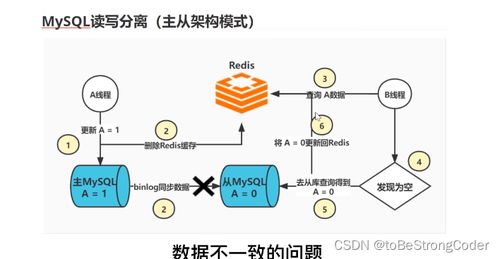
- 读写分离与缓存更新:将主库的实时变更同步至只读从库或Redis缓存,提升查询性能。
- 数据仓库(ODS)构建:将多个业务库的订单、交易数据实时汇聚至数据仓库,支撑实时分析与报表。
- 跨微服务数据共享:在保证服务自治的前提下,将用户中心的核心数据变更同步至其他业务库,避免频繁的跨服务接口调用。
- 数据备份与容灾:实现异地、异数据库的实时数据备份,为灾难恢复提供支持。
五、与展望
Porter作为随行付微服务生态的重要基础设施,成功解决了分布式环境下的数据流动难题,提升了研发效率与系统可靠性。其设计充分体现了关注点分离、最终一致性与可观测性等现代软件工程原则。Porter将继续向智能化运维、更丰富的数据源/目标支持(如MongoDB, PostgreSQL)、以及流式数据处理能力等方向演进,以更好地支撑随行付业务的快速发展。
通过Porter的实践,随行付团队不仅打造了一个高效的数据同步工具,更深化了对微服务架构下数据治理的理解,为构建稳定、敏捷的金融科技系统奠定了坚实的数据基石。